AI Keyword Extractor
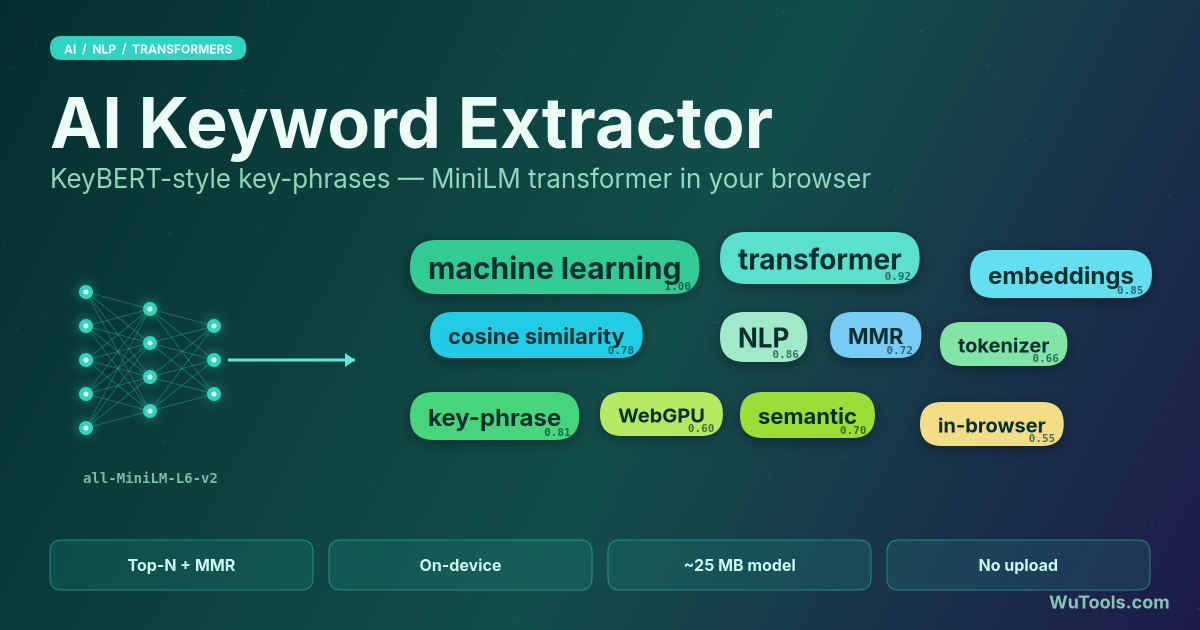
On-device AI keyword extractor: no upload, runs a MiniLM transformer (384-dim, ~23 MB) in your browser. KeyBERT MMR ranking for SEO key phrases.
About the AI Keyword Extractor
The AI Keyword Extractor identifies the most semantically representative words and short phrases in any text. It runs the KeyBERT pipeline entirely in your browser using a sentence-transformer model with WebGPU acceleration, so confidential text never leaves your device. Adjustable diversity and phrase length let you fine-tune the result for SEO research, meeting transcripts, or topic discovery. See also our AI translator and AI image caption generator.
How is this different from a simple TF-IDF keyword extractor?
Term-frequency methods like TF-IDF rank phrases by how often they appear in the document compared to a reference corpus. They are fast but blind to meaning, so they over-rank rare proper nouns and under-rank conceptually central phrases that happen to be rephrased throughout the text. This tool uses the all-MiniLM-L6-v2 sentence-transformer, which maps both the document and every candidate phrase into a 384-dimensional semantic space and ranks by cosine similarity. As a result, a paragraph that discusses 'neural networks' using varied wording (deep learning, hidden layers, backpropagation) will still surface 'neural networks' as a top keyword, even if it appears only once - because its embedding sits at the centre of the conceptual cloud formed by the rest of the text.
What is Maximal Marginal Relevance (MMR) and why does it matter?
MMR is a re-ranking algorithm introduced by Carbonell and Goldstein in 1998 that picks each new item by balancing two scores: its similarity to the query (here, the document embedding) and its dissimilarity to items already selected. A lambda parameter (mapped to the inverted Diversity slider in this tool) controls the trade-off. Without MMR, a transformer-based extractor tends to return long lists of near-duplicates because the top-K phrases sit close together in embedding space. With MMR turned up, the list still stays on-topic but spreads across the conceptual surface of the document, giving you a much richer overview, which is what you usually want for content briefs, topic clusters, or research summaries.
Does my text get uploaded anywhere?
No. The model file is fetched once from the Hugging Face CDN (the same way any JavaScript library is fetched) and cached by your browser. Once loaded, all inference happens inside a Web Worker on your own CPU or GPU. The text you paste, the candidate phrases, and the final embeddings are never sent over the network. You can verify this by watching the Network tab in your browser's DevTools - after the initial model files load, you should see zero outgoing requests when you click Extract. This local-only design makes the tool safe for confidential documents, NDAs, customer transcripts, and unpublished writing.
Why does the first run take much longer than the second?
On the first run, your browser has to download the model weights (~23 MB for the distilled MiniLM checkpoint plus a small tokenizer), uncompress them, and JIT-compile the WebAssembly or WebGPU kernels that run the matrix multiplications. After that, the files sit in the Cache Storage API and the kernels stay warm in the worker, so subsequent extractions usually finish in under a second for documents of a few thousand words. If you clear your browser cache, the download will happen again. On a slow connection the first run can take 20-40 seconds; a fast connection plus WebGPU brings it under 5 seconds.
Why does the extractor sometimes return obvious stop-words inside a phrase?
The candidate generator discards phrases whose first or last token is a stop-word, but it deliberately allows stop-words in the middle. This is on purpose: phrases like 'rate of return', 'state of the art', or 'cost of living' carry real meaning even though they contain 'of' or 'the'. If you want stricter output, drop the phrase length down to 1-2 words; if you want maximum readability, leave it at 1-3 and let the MMR step surface only the strongest cohesive phrases. The score column in the plain-list output lets you filter aggressively (for example, keep only entries with score >= 0.4).
What does the score number actually mean, and what threshold should I trust?
Each score is the cosine similarity (0 to 1) between the candidate phrase's embedding and the document embedding, so it measures how semantically central the phrase is to the whole text - not how often it appears. As a practical calibration: scores at or above 0.5 indicate a phrase that sits close to the core topic and is almost always worth keeping; 0.4 to 0.5 is solidly on-topic and a good default floor for SEO briefs and topic clusters; 0.3 to 0.4 is loosely related and useful mainly for breadth; below 0.3 the phrase is usually noise. Use the Minimum relevance score slider above the export buttons to gate the list at a confidence floor in real time and re-export only the phrases that clear it. One caveat for very long inputs: only the first 8000 characters are analysed, and although the document embedding now spans that entire window via chunked mean-pooling, content past the 8000-character cut-off is not scored at all - split book-length text into sections if you need full coverage.
Can I process multiple articles and export the keywords to a spreadsheet?
Yes. Run each article through the tool one at a time, set the Minimum relevance score slider to your preferred floor (0.4 is a sensible default), then click CSV to download phrase, score and count columns that open directly in Excel, Google Sheets, or any data tool - or JSON if you are feeding a script, and Markdown for a quick table in your CMS. Because the threshold slider filters the list before export, the file you get contains only the high-confidence keywords, so you can paste several articles' exports into one master sheet and pivot or de-duplicate to build a content cluster without hand-cleaning low-score rows. All extraction stays on-device, so even an unpublished batch of drafts never leaves your machine.
What languages does the model support?
The all-MiniLM-L6-v2 checkpoint used here was trained primarily on English, so English documents give the highest-quality output. The model still produces useful embeddings for the closely related Romance and Germanic languages (Spanish, Portuguese, French, German, Italian) - extraction will work and the top results will mostly be sensible, but score calibration is less reliable. For Vietnamese, Chinese, Japanese, Korean, Arabic, and other languages with different character sets, a multilingual checkpoint such as paraphrase-multilingual-MiniLM-L12-v2 would be more accurate. We may add a model picker in a future release; for now you can use this tool comfortably on English content and exploratorily on Romance-language content.
- AI Depth Estimator
- AI Grammar Corrector
- AI Object Detector
- AI Pose Estimator
- AI Speech to Text
- AI Style Transfer
- AI Text Summarizer
- AI image caption generator
- AI keyword extractor
- AI translator
- Age & Gender Predictor
- Face Beautify
- Face Blur
- Face Similarity Meter
- Image to Prompt Generator
- Language Detector
- Prompt Token Budget Planner
- YouTube Summarizer
- AI Background Remover

- AI Context Bundler

- AI Image Upscaler
- AI Music Genre Classifier

- AI Object Remover
- AI Vocal Remover
- Audio to MIDI
- Auto Subtitle Generator

- Background Replacer
- Blur Video Area Pro