Extracteur de Mots-Clés IA
Extracteur de mots-clés IA sur l'appareil : sans envoi, un transformer MiniLM (384-dim, ~23 Mo) dans le navigateur. Classement KeyBERT MMR pour le SEO.
À propos de l'Extracteur de Mots-Clés IA
L'Extracteur de Mots-Clés IA identifie les mots et expressions courtes les plus représentatifs sémantiquement dans n'importe quel texte. Il exécute le pipeline KeyBERT entièrement dans votre navigateur via un modèle sentence-transformer accéléré par WebGPU, donc les textes confidentiels ne quittent jamais l'appareil. Diversité et longueur de phrase ajustables pour la recherche SEO, transcriptions de réunions ou découverte de sujets. Voir aussi notre Traducteur IA et notre Générateur de légendes dimage.
En quoi cela diffère-t-il d'un extracteur TF-IDF simple ?
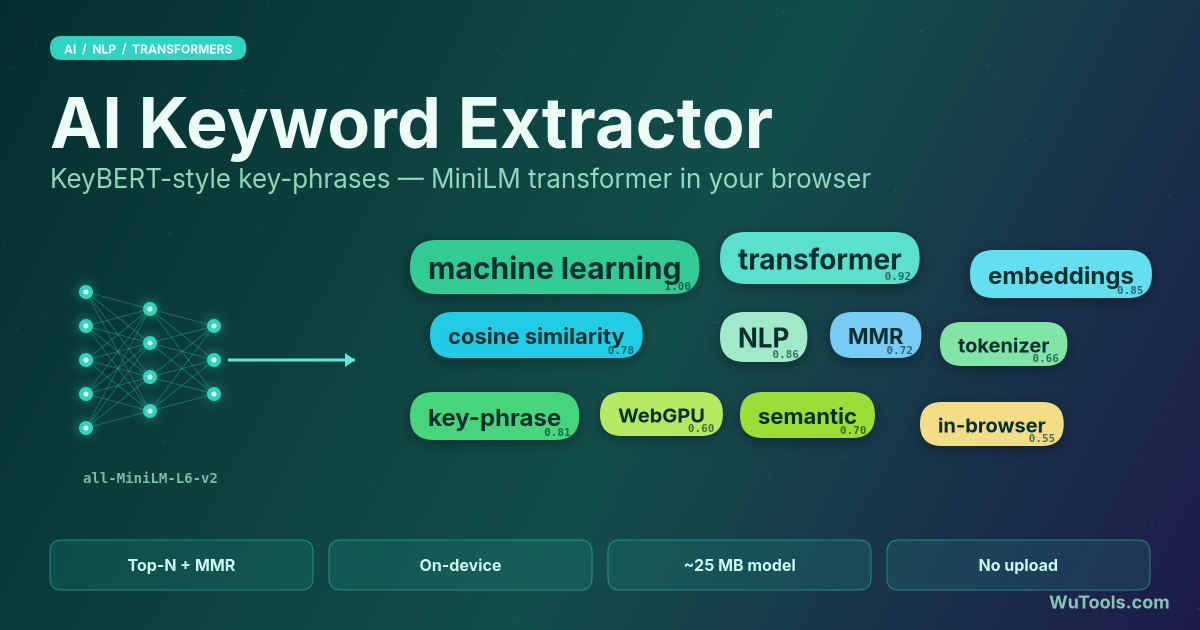
Les méthodes basées sur la fréquence des termes comme TF-IDF classent les expressions selon le nombre de fois où elles apparaissent par rapport à un corpus de référence. Elles sont rapides mais aveugles au sens, donc elles surclassent les noms propres rares et sous-évaluent les expressions conceptuellement centrales reformulées dans le texte. Cet outil utilise le sentence-transformer all-MiniLM-L6-v2, qui projette le document et chaque expression candidate dans un espace sémantique à 384 dimensions et les classe par similarité cosinus. Résultat : un paragraphe qui traite de 'réseaux de neurones' avec un vocabulaire varié (apprentissage profond, couches cachées, rétropropagation) gardera 'réseaux de neurones' en tête, même si l'expression n'apparaît qu'une fois, parce que son embedding est au centre du nuage conceptuel.
Qu'est-ce que Maximal Marginal Relevance (MMR) et pourquoi est-ce important ?
MMR est un algorithme de re-classement introduit par Carbonell et Goldstein en 1998 qui choisit chaque nouvel élément en équilibrant deux scores : sa similarité avec la requête (ici, l'embedding du document) et sa dissimilarité par rapport aux éléments déjà sélectionnés. Un paramètre lambda (mappé au curseur inversé de Diversité) contrôle ce compromis. Sans MMR, les extracteurs basés sur transformer renvoient souvent des listes de quasi-doublons car les K meilleures expressions sont proches dans l'espace d'embeddings. Avec MMR élevé, la liste reste pertinente mais se déploie sur la surface conceptuelle du document, offrant une vue beaucoup plus riche - idéale pour les briefs de contenu, clusters thématiques ou résumés de recherche.
Mon texte est-il envoyé quelque part ?
Non. Le fichier du modèle est téléchargé une fois depuis le CDN Hugging Face (comme n'importe quelle bibliothèque JavaScript) et conservé en cache par le navigateur. Ensuite, toute l'inférence se déroule dans un Web Worker sur votre CPU ou GPU. Le texte que vous collez, les expressions candidates et les embeddings finaux ne quittent pas l'appareil. Vous pouvez le vérifier dans l'onglet Réseau des DevTools : après le téléchargement initial du modèle, aucune requête sortante n'est faite quand vous cliquez sur Extraire. Cette conception purement locale rend l'outil sûr pour documents confidentiels, NDA, transcriptions clients et brouillons non publiés.
Pourquoi la première exécution prend-elle beaucoup plus de temps que la seconde ?
Lors de la première exécution, le navigateur doit télécharger les poids du modèle (~23 Mo pour le checkpoint MiniLM distillé plus un petit tokenizer), les décompresser et compiler à la volée les kernels WebAssembly ou WebGPU qui effectuent les multiplications matricielles. Ensuite, les fichiers restent dans la Cache Storage API et les kernels demeurent chauds dans le worker, si bien que les extractions suivantes s'achèvent en moins d'une seconde pour des documents de quelques milliers de mots. Si vous videz le cache, le téléchargement se reproduira. Sur connexion lente, la première exécution peut prendre 20-40 secondes ; avec une connexion rapide et WebGPU, on tombe sous les 5 secondes.
Pourquoi l'extracteur renvoie-t-il parfois des mots vides à l'intérieur d'une expression ?
Le générateur de candidats écarte les expressions dont le premier ou le dernier mot est un mot vide, mais autorise délibérément les mots vides au milieu. C'est volontaire : des expressions comme 'taux de rendement', 'état de l'art' ou 'coût de la vie' portent un vrai sens même si elles contiennent 'de' ou 'la'. Si vous voulez une sortie plus stricte, réduisez la longueur à 1-2 mots ; pour une lisibilité maximale, gardez 1-3 et laissez l'étape MMR mettre en avant les expressions les plus cohérentes. La colonne score de la liste simple permet un filtrage agressif (par exemple, garder uniquement les entrées avec score >= 0.4).
Que signifie réellement le score, et à quel seuil se fier ?
Chaque score est la similarité cosinus (de 0 à 1) entre l'embedding de l'expression candidate et celui du document ; il mesure donc à quel point l'expression est centrale pour l'ensemble du texte, et non son nombre d'occurrences. Calibrage pratique : un score de 0.5 ou plus indique une expression très proche du cœur du sujet, presque toujours à conserver ; de 0.4 à 0.5, elle est solidement dans le thème et constitue un bon seuil par défaut pour les briefs SEO et les clusters thématiques ; de 0.3 à 0.4, le lien est lâche et utile surtout pour élargir ; en dessous de 0.3, c'est généralement du bruit. Utilisez le curseur Score de pertinence minimum situé au-dessus des boutons d'export pour filtrer la liste en temps réel et n'exporter que les expressions qui franchissent le seuil. Une réserve pour les entrées très longues : seuls les 8000 premiers caractères sont analysés et, même si l'embedding du document couvre désormais toute cette fenêtre via la moyenne par blocs, le contenu au-delà de la coupure à 8000 caractères n'est pas noté - découpez les textes très longs en sections si une couverture totale est nécessaire.
Puis-je traiter plusieurs articles et exporter les mots-clés vers un tableur ?
Oui. Passez chaque article dans l'outil un par un, réglez le curseur Score de pertinence minimum au seuil souhaité (0.4 est une valeur raisonnable), puis cliquez sur CSV pour télécharger des colonnes expression, score et occurrences qui s'ouvrent directement dans Excel, Google Sheets ou tout outil de données - ou JSON si vous alimentez un script, et Markdown pour un tableau rapide dans votre CMS. Comme le curseur filtre la liste avant l'export, le fichier ne contient que les mots-clés à forte confiance, vous pouvez donc coller les exports de plusieurs articles dans une feuille maîtresse et faire un tableau croisé ou dédupliquer pour bâtir un cluster de contenu sans nettoyer à la main les lignes à faible score. Toute l'extraction s'effectue sur l'appareil, donc même un lot de brouillons non publiés ne quitte pas votre machine.
Quelles langues le modèle prend-il en charge ?
Le checkpoint all-MiniLM-L6-v2 utilisé ici a été entraîné principalement en anglais, donc les documents anglais offrent la meilleure qualité. Le modèle produit néanmoins des embeddings utiles pour les langues romanes et germaniques proches (espagnol, portugais, français, allemand, italien) - l'extraction fonctionne et les résultats sont globalement sensés, mais le calibrage des scores est moins fiable. Pour le vietnamien, le chinois, le japonais, le coréen, l'arabe et d'autres langues à jeux de caractères différents, un checkpoint multilingue comme paraphrase-multilingual-MiniLM-L12-v2 serait plus précis. Nous pourrions ajouter un sélecteur de modèle dans une future version ; en attendant, utilisez l'outil avec confiance sur du contenu anglais et de manière exploratoire pour les langues romanes.
- Convertisseur Voix en Texte
- Correcteur Grammatical IA
- Détecteur d'Objets AI
- Détecteur de Langue
- Embellisseur Facial
- Estimateur de Poses AI
- Estimateur de Profondeur AI
- Extracteur de mots-clés IA
- Flouter Visages
- Générateur de légendes d'image
- Image vers Prompt
- Mesureur de Similitude Faciale
- Planificateur de Tokens
- Prédicteur d'Âge et de Genre
- Résumeur YouTube
- Résumeur de Texte IA
- Traducteur IA
- Transfert de Style IA
- Agrandisseur d'Image IA

- Audio vers MIDI

- Classificateur de Genres Musicaux IA
- Empaqueteur Contexte IA

- Flouter Zone Vidéo Pro

- Générateur de Sous-titres
- Photo en Anime
- Remplacer l'Arrière-Plan
- Suppresseur d'Arrière-Plan IA
- Suppresseur d'Objets